Imagine, somewhere in the internet that no-one trusts, there is a piece of hardware, a small computer, that works just for you. You can trust it. You can depend on it. Things may get rough but it will stay there to get you through. That is Nikka, it is the fixed point on which you can build your security and trust. [Now as a Kickstarter project]
You may remember our proof-of-concept implementation of a password protection for servers – Hardware Scrambling (published here in March). The password scrambler was a small dongle that could be plugged to a Linux computer (we used Raspberry Pi). Its only purpose was to provide a simple API for encrypting passwords (but it could be credit cards or anything else up to 32 bytes of length). The beginning of something big?
It received some attention (Ars Technica, Slashdot, LWN, …), certainly more than we expected at the time. Following discussions have also taught us a couple of lessons about how people (mostly geeks in this contexts) view security – particularly about the default distrust expressed by those who discussed articles describing our password scrambler.
We eventually decided to build a proper hardware cryptographic platform that could be used for cloud applications. Our requirements were simple. We wanted something fast, “secure” (CC EAL5+ or even FIPS140-2 certified), scalable, easy to use (no complicated API, just one function call) and to be provided as a service so no-one has to pay upfront the price of an HSM if they just want to have a go at using proper cryptography for their new or old application. That was the beginning of Nikka.
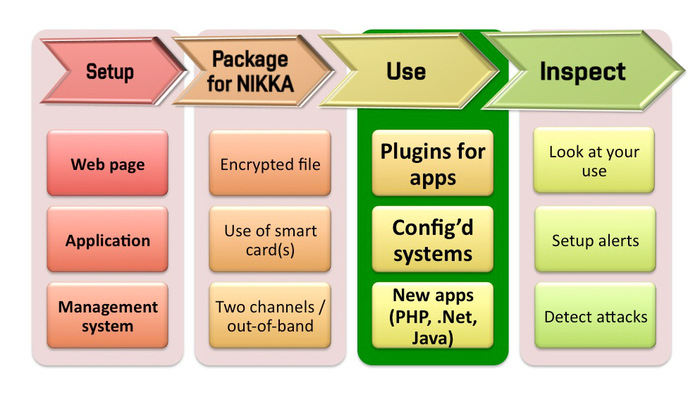
This is our concept: Nikka comprises a set of powerful servers installed in secure data centres. These servers can create clusters delivering high-availability and scalability for their clients. Secure hardware forms the backbone of each server that provides an interface for simple use. The second part of Nikka are user applications, plugins, and libraries for easy deployment and everyday “invisible” use. Operational procedures, processes, policies, and audit logs then guarantee that what we say is actually being done.
 We have been building it for a few months now and the scalable cryptographic core seems to work. We have managed to run long-term tests of 150 HMAC transactions per second (HMAC & RNG for password scrambling) on a small development platform while fully utilising available secure hardware. The server is hosted at ideaSpace and we use it to run functional, configuration and load tests.
We have been building it for a few months now and the scalable cryptographic core seems to work. We have managed to run long-term tests of 150 HMAC transactions per second (HMAC & RNG for password scrambling) on a small development platform while fully utilising available secure hardware. The server is hosted at ideaSpace and we use it to run functional, configuration and load tests.
We have never before designed a system with so many independent processes – the core is completely asynchronous (starting with Netty for a TCP interface) and we have quickly started to appreciate detailed trace logging we’ve implemented from the very beginning. Each time we start digging we find something interesting. Real-time visualisation of the performance is quite nice as well.
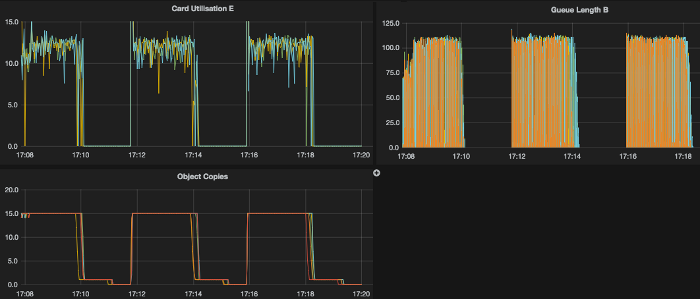
Nikka is basically a general purpose cryptographic engine with middleware layer for easy integration. The password HMAC is this time used only as one of test applications. Users can share or reserve processing units that have Common Criteria evaluations or even FIPS140-2 certification – with possible physical hardware separation of users.
If you like what you have read so far, you can keep reading, watching, supporting at Kickstarter. It has been great fun so far and we want to turn it into something useful in 2015. If it sounds interesting – maybe you would like to test it early next year, let us know! @DanCvrcek
