Google has a number of restrictions on what can be advertised on their advert serving platforms. They don’t allow adverts for services that “cause damage, harm, or injury” and they don’t allow adverts for services that “are designed to enable dishonest behavior“.
Google don’t seem to have an explicit policy that says you cannot advertise a criminal enterprise : perhaps they think that is too obvious to state.
Nevertheless, the policies they written down might lead you to believe that advertising “booter” (or as they sometimes style themselves to appear more legitimate) “stresser” services would not be allowed. These are websites that allow anyone with a spare $5.00 or so to purchase distributed denial of service (DDoS) attacks.
Booters are mainly used by online game players to cheat — by knocking some of their opponents offline — or by pupils who down the school website to postpone an online test or just because they feel like it. You can purchase attacks for any reason (and attack any Internet system) that you want.
These booter sites are quite clearly illegal — there have been recent arrests in Israel and the Netherlands and in the UK Adam Mudd got two years (reduced to 21 months on appeal) for running a booter service. In the USA a New Mexico man recently got a fifteen year sentence for merely purchasing attacks from these sites (and for firearms charges as well).
However, Google doesn’t seem to mind booter websites advertising their wares on their platform. This advert was served up a couple of weeks back:
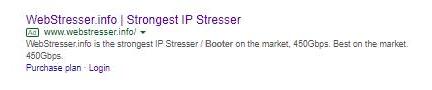
I complained using Google’s web form — after all, they serve up lots of adverts and their robots may not spot all the wickedness. That’s why they have reporting channels to allow them to correct mistakes. Nothing happened until I reached out to a Google employee (who spends a chunk of his time defending Google from DDoS attacks) and then finally the advert disappeared.
Last week another booter advert appeared:
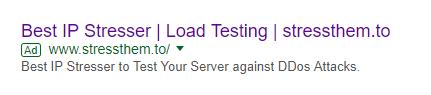
but another complaint also made no difference and this time my contact failed to have any impact either, and so at the time of writing the advert is still there.
It seems to me that, for Google, income is currently more important than enforcing policies.