Here is a video of a talk I gave at DMU on security economics (and the slides). I’ve given variants of this survey talk at various conferences over the past two or three years; at last one of them recorded the talk and put the video online. There’s also a survey paper that covers much of the same material. If you find this interesting, you might enjoy coming along to WEIS (the Workshop on the Economics of Information Security) on June 24-25.
Category Archives: Academic papers
Temporal Correlations between Spam and Phishing Websites
Richard Clayton and I have been studying phishing website take-down for some time. We monitored the availability of phishing websites, finding that while most phishing websites are removed with a day or two, a substantial minority remain for much longer. We later found that one of the main reasons why so many websites slip through the cracks is that the take-down companies responsible for removal refuse to share their URL lists with each other.
One nagging question remained, however. Do long-lived phishing websites cause any harm? Would removing them actually help? To get that answer, we had to bring together data on the timing of phishing spam transmission (generously shared by Cisco IronPort) with our existing data on phishing website lifetimes. In our paper co-authored with Henry Stern and presented this week at the USENIX LEET Workshop in Boston, we describe how a substantial portion of long-lived phishing websites continue to receive new spam until the website is removed. For instance, fresh spam continues to be sent out for 75% of phishing websites alive after one week, attracting new victims. Furthermore, around 60% of phishing websites still alive after a month keep receiving spam advertisements.
Consequently, removal of websites by the banks (and the specialist take-down companies they hire) is important. Even when the sites stay up for some time, there is value in continued efforts to get them removed, because this will limit the damage.
However, as we have pointed out before, the take-down companies cause considerable damage by their continuing refusal to share data on phishing attacks with each other, despite our proposals addressing their competitive concerns. Our (rough) estimate of the financial harm due to longer-lived phishing websites was $330 million per year. Given this new evidence of persistent spam campaigns, we are now more confident of this measure of harm.
There are other interesting insights discussed in our new paper. For instance, phishing attacks can be broken down into two main categories: ordinary phishing hosted on compromised web servers and fast-flux phishing hosted on a botnet infrastructure. It turns out that fast-flux phishing spam is more tightly correlated with the uptime of the associated phishing host. Most spam is sent out around the time the fast-flux website first appears and stops once the website is removed. For phishing websites hosted on compromised web servers, there is much greater variation between the time a website appears and when the spam is sent. Furthermore, fast-flux phishing spam was 68% of the total email spam detected by IronPort, despite this being only 3% of all the websites.
So there seems to be a cottage industry of fairly disorganized phishing attacks, with perhaps a few hundred people involved. Each compromises a small number of websites, while sending a small amount of spam. Conversely there are a small number of organized gangs who use botnets for hosting, send most of the spam, and are extremely efficient on every measure we consider. We understand that the police are concentrating their efforts on the second set of criminals. This appears to be a sound decision.
Facebook Giving a Bit Too Much Away
Facebook has been serving up public listings for over a year now. Unlike most of the site, anybody can view public listings, even non-members. They offer a window into the Facebook world for those who haven’t joined yet, since Facebook doesn’t allow full profiles to be publicly viewable by non-members (unlike MySpace and others). Of course, this window into Facebook comes with a prominent “Sign Up” button, growth still being the main mark of success in the social networking world. The goal is for non-members to stumble across a public listing, see how many friends are already using Facebook, and then join. Economists call this a network effect, and Facebook is shrewdly harnessing it.
Of course, to do this, Facebook is making public every user’s name, photo, and 8 friendship links. Affiliations with organizations, causes, or products are also listed, I just don’t have any on my profile (though my sister does). This is quite a bit of information given away by a feature many active Facebook user are unaware of. Indeed, it’s more information than the Facebook’s own privacy policy indicates is given away. When the feature was launched in 2007, every over-18 user was automatically opted-in, as have been new users since then. You can opt out, but few people do-out of more than 500 friends of mine, only 3 had taken the time to opt out. It doesn’t help that most users are unaware of the feature, since registered users don’t encounter it.
Making matters worse, public listings aren’t protected from crawling. In fact they are designed to be indexed by search engines. In our own experiments, we were able to download over 250,000 public listings per day using a desktop PC and a fairly crude Python script. For a serious data aggregator getting every user’s listing is no sweat. So what can one do with 200 million public listings?
I explored this question along with Jonathan Anderson, Frank Stajano, and Ross Anderson in a new paper which we presented today at the ACM Social Network Systems Workshop in Nuremberg. Facebook’s public listings give us a random sample of the social graph, leading to some interesting exercises in graph theory. As we describe in the paper, it turns out that this sampled graph allows us to approximate many properties of the complete network surprisingly well: degree and centrality of nodes, small dominating sets, short paths, and community structure. These are all things marketers and sociologists alike would love to know for the complete Facebook graph.
This result leads to two interesting conclusions. First, protecting a social graph is hard. Consistent with previous results, we found that giving away a seemingly small amount can allow much information to be inferred. It’s also been shown that anonymising a social graph is almost impossible.
Second, Facebook is developing a track record of releasing features and then being surprised by the privacy implications, from Beacon to NewsFeed and now Public Search. Analogous to security-critical software, where new code is extensively tested and evaluated before being deployed, social networks should have a formal privacy review of all new features before they are rolled out (as, indeed, should other web services which collect personal information). Features like public search listings shouldn’t make it off the drawing board.
The Snooping Dragon
There’s been much interest today in a report that Shishir Nagaraja and I wrote on Chinese surveillance of the Tibetan movement. In September last year, Shishir spent some time cleaning out Chinese malware from the computers of the Dalai Lama’s private office in Dharamsala, and what we learned was somewhat disturbing.
Later, colleagues from the University of Toronto followed through by hacking into one of the control servers Shishir identified (something we couldn’t do here because of the Computer Misuse Act); their report relates how the attackers had controlled malware on hundreds of other PCs, many in government agencies of countries such as India, Vietnam and the Phillippines, but also in US firms such as AP and Deloittes.
The story broke today in the New York Times; see also coverage in the Telegraph, the BBC, CNN, the Times of India, AP, InfoWorld, Wired and the Wall Street Journal.
Hot Topics in Privacy Enhancing Technologies (HotPETs 2009)
HotPETs – the 2nd Hot Topics in Privacy Enhancing Technologies (co-located with PETS) will be held in Seattle, 5–7 August 2009.
HotPETs is the forum for new ideas on privacy, anonymity, censorship resistance, and related topics. Work-in-progress is welcomed, and the format of the workshop will be to encourage feedback and discussion. Submissions are especially encouraged on the human side of privacy: what do people believe about privacy? How does privacy work in existing institutions?
Papers (up to 15 pages) are due by 8 May 2009. Further information can be found in the call for papers.
Optimised to fail: Card readers for online banking
A number of UK banks are distributing hand-held card readers for authenticating customers, in the hope of stemming the soaring levels of online banking fraud. As the underlying protocol — CAP — is secret, we reverse-engineered the system and discovered a number of security vulnerabilities. Our results have been published as “Optimised to fail: Card readers for online banking”, by Saar Drimer, Steven J. Murdoch, and Ross Anderson.
In the paper, presented today at Financial Cryptography 2009, we discuss the consequences of CAP having been optimised to reduce both the costs to the bank and the amount of typing done by customers. While the principle of CAP — two factor transaction authentication — is sound, the flawed implementation in the UK puts customers at risk of fraud, or worse.
When Chip & PIN was introduced for point-of-sale, the effective liability for fraud was shifted to customers. While the banking code says that customers are not liable unless they were negligent, it is up to the bank to define negligence. In practice, the mere fact that Chip & PIN was used is considered enough. Now that Chip & PIN is used for online banking, we may see a similar reduction of consumer protection.
Further information can be found in the paper and the talk slides.
Evil Searching
Tyler Moore and I have been looking into how phishing attackers locate insecure websites on which to host their fake webpages, and our paper is being presented this week at the Financial Cryptography conference in Barbados. We found that compromised machines accounted for 75.8% of all the attacks, “free” web hosting accounts for 17.4%, and the rest is various specialist gangs — albeit those gangs should not be ignored; they’re sending most of the phishing spam and (probably) scooping most of the money!
Sometimes the same machine gets compromised more than once. Now this could be the same person setting up multiple phishing sites on a machine that they can attack at will… However, we often observe that the new site is in a completely different directory — strongly suggesting a different attacker has broken into the same machine, but in a different way. We looked at all the recompromises where there was a delay of at least a week before the second attack and found that in 83% of cases a different directory was used… and using this definition of a “recompromise” we found that around 10% of machines were recompromised within 4 weeks, rising to 20% after six months. Since there’s a lot of vulnerable machines out there, there is something slightly different about the machines that get attacked again and again.
For 2486 sites we also had summary website logging data from The Webalizer; where sites had left their daily visitor statistics world-readable. One of the bits of data The Webalizer documents is which search terms were used to locate the website (because these are available in the “Referrer” header, and that will document what was typed into search engines such as Google).
We found that some of these searches were “evil” in that they were looking for specific versions of software that contained security vulnerabilities (“If you’re running version 1.024 then I can break in”); or they were looking for existing phishing websites (“if you can break in, then so can I”); or they were seeking the PHP “shells” that phishing attackers often install to help them upload files onto the website (“if you haven’t password protected your shell, then I can upload files as well”).
In all, we found “evil searches” on 204 machines that hosted phishing websites AND that, in the vast majority of cases, these searches corresponded in time to when the website was broken into. Furthermore, in 25 cases the website was compromised twice and we were monitoring the daily log summaries after the first break-in: here 4 of the evil searches occurred before the second break in, 20 on the day of the second break in, and just one after the second break-in. Of course, where people didn’t “click through” from Google search results, perhaps because they had an automated tool, then we won’t have a record of their searches — but neverthless, even at the 18% incidence we can be sure of, searches are an important mechanism.
The recompromise rates for sites where we found evil searches were a lot higher: 20% recompromised after 4 weeks, nearly 50% after six months. There are lots of complicating factors here, not least that sites with world-readable Webalizer data might simply be inherently less secure. However, overall we believe that it clearly indicates that the phishing attackers are using search to find machines to attack; and that if one attacker can find the site, then it is likely that others will do so independently.
There’s a lot more in the paper itself (which is well-worth reading before commenting on this article, since it goes into much more detail than is possible here)… In particular, we show that publishing URLs in PhishTank slightly decreases the recompromise rate (getting the sites fixed is a bigger effect than the bad guys locating sites that someone else has compromised); and we also have a detailed discussion of various mitigation strategies that might be employed, now that we have firmly established that “evil searching” is an important way of locating machines to compromise.
Security issues in ubiquitous computing
I have written the security chapter for a multi-author volume on ubiquitous computing that will be published by Springer later this year. For me it was an opportunity to pull together some of the material I have been collecting for a possible second edition of my 2002 book on Security for Ubiquitous Computing—but of course a 30-page chapter can be nothing more than a brief introduction.
Anyway, here is a “release candidate” copy of the chapter, which will ship to the book editors in a couple of weeks. Comments are welcome, either on the chapter itself or, based on this preview, on what you’d like me to discuss in my own full-length book when I yield to the repeated pleas of John Wiley And Sons and sit down to write a new edition.
Forensic genomics
I recently presented a paper on Forensic genomics: kin privacy, driftnets and other open questions (co-authored with Lucia Bianchi, Pietro Liò and Douwe Korff) at WPES 2008, the Workshop for Privacy in the Electronic Society of ACM CCS, the ACM Computer and Communication Security conference. Pietro and I also gave a related talk here at the Computer Laboratory in Cambridge.
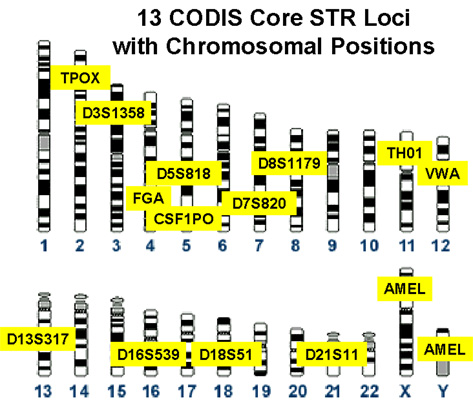
While genetics is concerned with the observation of specific sections of DNA, genomics is about studying the entire genome of an organism, something that has only become practically possible in recent years. In forensic genetics, which is the technology behind the large national DNA databases being built in several countries including notably UK and USA (Wallace’s outstanding article lucidly exposes many significant issues), investigators compare scene-of-crime samples with database samples by checking if they match, but only on a very small number of specific locations in the genome (e.g. 13 locations according to the CODIS rules). In our paper we explore what might change when forensic analysis moves from genetics to genomics over the next few decades. This is a problem that can only be meaningfully approached from a multi-disciplinary viewpoint and indeed our combined backgrounds cover computer security, bioinformatics and law.
(Image from Wikimedia commons, in turn from NIST.)
{kind=link}
Sequencing the first human genome (2003) cost 2.7 billion dollars and took 13 years. The US’s National Human Genome Research Institute has offered over 20 M$ worth of grants towards the goal of driving the cost of whole-genome sequencing down to a thousand dollars. This will enable personalized genomic medicine (e.g. predicting genetic risk of contracting specific diseases) but will also open up a number of ethical and privacy-related problems. Eugenetic abortions, genomic pre-screening as precondition for healthcare (or even just dating…), (mis)use of genomic data for purposes other than that for which it was collected and so forth. In various jurisdictions there exists legislation (such as the recent GINA in the US) that attempts to protect citizens from some of the possible abuses; but how strongly is it enforced? And is it enough? In the forensic context, is the DNA analysis procedure as infallible as we are led to believe? There are many subtleties associated with the interpretation of statistical results; when even professional statisticians disagree, how are the poor jurors expected to reach a fair verdict? Another subtle issue is kin privacy: if the scene-of-crime sample, compared with everyone in the database, partially matches Alice, this may be used as a hint to investigate all her relatives, who aren’t even in the database; indeed, some 1980s murders were recently solved in this way. “This raises compelling policy questions about the balance between collective security and individual privacy” [Bieber, Brenner, Lazer, 2006]. Should a democracy allow such a “driftnet” approach of suspecting and investigating all the innocents in order to catch the guilty?
This is a paper of questions rather than one of solutions. We believe an informed public debate is needed before the expected transition from genetics to genomics takes place. We want to stimulate discussion and therefore we invite you to read the paper, make up your mind and support what you believe are the right answers.
How can we co-operate to tackle phishing?
Richard Clayton and I recently presented evidence of the adverse impact of take-down companies not sharing phishing feeds. Many phishing websites are missed by the take-down company which has the contract for removal; unsurprisingly, these websites are not removed very fast. Consequently, more consumers’ identities are stolen.
In the paper, we propose a simple solution: take-down companies should share their raw, unverified feeds of phishing URLs with their competitors. Each company can examine the raw feed, pick out the websites impersonating their clients, and focus on removing these sites.
Since we presented our findings to the Anti-Phishing Working Group eCrime Researchers Summit, we have received considerable feedback from take-down companies. Take-down companies attending the APWG meeting understood that sharing would help speed up response times, but expressed reservations at sharing their feeds unless they were duly compensated. Eric Olsen of Cyveillance (another company offering take-down services) has written a comprehensive rebuttal of our recommendations. He argues that competition between take-down companies drives investment in efforts to detect more websites. Mandated sharing of phishing URL feeds, in his view, would undermine these detection efforts and cause take-down companies such as Cyveillance to exit the business.
I do have some sympathy for the objections raised by the take-down companies. As we state in the paper, free-riding (where one company relies on another to invest in detection so they don’t have to) is a concern for any sharing regime. Academic research studying other areas of information security (e.g., here and here), however, has shown that free-riding is unlikely to be so rampant as to drive all the best take-down companies out of offering service, as Mr. Olsen suggests.
While we can quibble over the extent of the threat from free free-riding, it should not detract from the conclusions we draw over the need for greater sharing. In our view, it would be unwise and irresponsible to accept the current status quo of keeping phishing URL feeds completely private. After all, competition without sharing has approximately doubled the lifetimes of phishing websites! The solution, then, is to devise a sharing mechanism that gives take-down companies the incentive to keep detecting more phishing URLs.
Continue reading How can we co-operate to tackle phishing?