
Memory safety bugs continue to be a major source of security vulnerabilities, with their root causes ingrained in the industry:
- the C and C++ systems programming languages that do not enforce memory protection, and the huge legacy codebase written in them that we depend on;
- the legacy design choices of hardware that provides only coarse-grain protection mechanisms, based on virtual memory; and
- test-and-debug development methods, in which only a tiny fraction of all possible execution paths can be checked, leaving ample unexplored corners for exploitable bugs.
Over the last twelve years, the CHERI project has been working on addressing the first two of these problems by extending conventional hardware Instruction-Set Architectures (ISAs) with new architectural features to enable fine-grained memory protection and highly scalable software compartmentalisation, prototyped first as CHERI-MIPS and CHERI-RISC-V architecture designs and FPGA implementations, with an extensive software stack ported to run above them.
The academic experimental results are very promising, but achieving widespread adoption of CHERI needs an industry-scale evaluation of a high-performance silicon processor implementation and software stack. To that end, Arm have developed Morello, a CHERI-enabled prototype architecture (extending Armv8.2-A), processor (adapting the high-performance Neoverse N1 design), system-on-chip (SoC), and development board, within the UKRI Digital Security by Design (DSbD) Programme (see our earlier blog post on Morello). Morello is now being evaluated in a range of academic and industry projects.


However, how do we ensure that such a new architecture actually provides the security guarantees it aims to provide? This is crucial: any security flaw in the architecture will be present in any conforming hardware implementation, quite likely impossible to fix or work around after deployment.
In this blog post, we describe how we used rigorous engineering methods to provide high assurance of key security properties of CHERI architectures, with machine-checked mathematical proof, as well as to complement and support traditional design and development workflows, e.g. by automatically generating test suites. This is addressing the third problem, showing that, by judicious use of rigorous semantics at design time, we can do much better than test-and-debug development.
This is joint work by a team at Cambridge, Edinburgh, Arm, and SRI International, with the Morello proof and testing work mainly by Thomas Bauereiss, Brian Campbell, Thomas Sewell, and Alasdair Armstrong, and our earlier CHERI-MIPS proof by Kyndylan Nienhuis, as reported in:
- Verified Security for the Morello Capability-enhanced Prototype Arm Architecture. Thomas Bauereiss (1), Brian Campbell (2), Thomas Sewell (1), Alasdair Armstrong (1), Lawrence Esswood (1), Ian Stark (2), Graeme Barnes (3), Robert N. M. Watson (1), and Peter Sewell (1). In ESOP 2022.
- Rigorous engineering for hardware security: Formal modelling and proof in the CHERI design and implementation process. Kyndylan Nienhuis (1*), Alexandre Joannou (1), Thomas Bauereiss (1), Anthony Fox (1*), Michael Roe (1), Brian Campbell (2), Matthew Naylor (1), Robert M. Norton (1*), Simon W. Moore (1), Peter G. Neumann (4), Ian Stark (2), Robert N. M. Watson (1), and Peter Sewell (1). In Security and Privacy 2020.
(1) University of Cambridge, (2) University of Edinburgh, (3) Arm Ltd, (4) SRI International. (*) When this work was done. The academic CHERI project as a whole is led by Robert N. M. Watson, Simon W. Moore, and Peter Sewell at the University of Cambridge, and Peter G. Neumann at SRI International; together with (for Morello) a large team at Arm.
- 1 What is CHERI?
- 2 Complementing traditional engineering methods with rigorous semantics
- 3 Model-based test generation
- 4 Machine-checked mathematical proof of whole-ISA security properties
- 5 Design-time proof
- 6 Non-goals and limitations
- 7 Conclusion
- 8 Acknowledgements
1 What is CHERI?
The CHERI memory protection features allow existing C and C++ codebases, with only minimal source-code changes, to be run in an environment that provides strong and efficient protection against many currently widely exploited vulnerabilities. The CHERI scalable compartmentalisation features enable the fine-grained decomposition of operating-system and application code, to limit the effects of security vulnerabilities.
CHERI provides these via hardware support for unforgeable capabilities: in a CHERI ISA, instead of using simple 64-bit machine-word virtual-address pointer values to access memory, restricted only by the memory management unit, one can use 128+1-bit capabilities that encode a virtual address together with the base and bounds of the memory it can access. That enables a fast access-time check, faulting if there is a safety violation. A one-bit tag per capability-sized and aligned unit of memory, cleared in the hardware by any non-capability write and not directly addressable, ensures capability integrity by preventing forging, and the ISA design lets code shrink capabilities but never grow them.
This architectural mechanism, along with additional sealed-capability features for secure encapsulation, can be used by programming language implementations and systems software in many ways.
CHERI was first prototyped with CHERI-MIPS and CHERI-RISC-V FPGA hardware implementations, and substantial bodies of software have been ported to CHERI: an implementation of CHERI dialects of C and C++ in an adapted Clang/LLVM; a full UNIX OS, CheriBSD (based on FreeBSD); CHERI gdb; CheriFreeRTOS; Wayland+X11, KDE, OpenSSH; WebKit; PostgreSQL; and much more, described in this study of porting 6 million lines of code.
2 Complementing traditional engineering methods with rigorous semantics
Since 2014, we have been showing how more rigorous engineering methods can be used to improve assurance and complement test-and-debug traditional methods, with the CHERI project as a testbench. These include both lightweight methods – formal specification and testing methods that provide engineering and assurance benefits for hardware and software engineering without the challenges of full formal verification – and more heavyweight machine-checked proof, establishing very high confidence that the architecture design provides specific security properties.
We started for the original CHERI-MIPS and later CHERI-RISC-V designs by showing that prose-and-pseudocode ISA descriptions can be replaced in the architecture design process with rigorous definitions in our Sail instruction definition language (following earlier work using L3), which are at once:
- clearly readable (used directly in the documentation),
- executable as test oracles, and
- support automatic test generation.
Importantly, developing these did not require any formal background, so the researchers and engineers who would otherwise write a prose/pseudocode architecture document could write and own them.
At the same time, Sail automatically generates theorem-prover definitions, ensuring that the ISA definitions are mathematically rigorous, with no ambiguity. Formal specification alone is widely understood to bring low-cost clarity benefits, even before any proof work is undertaken. Here, our (more unusual) emphasis on specifications that are executable as test oracles and support test generation goes beyond that, and was essential for the integration of formal specification with traditional engineering. In turn, that ensured the specification was a conventionally well-validated “live artifact”: the actual ISA design, rather than a (possibly divergent) definition produced after the fact. This ensured that the following properties and proof are about the actual design.
The base RISC-V Sail specification that we developed as a starting point for CHERI-RISC-V, largely by Prashanth Mundkur and Robert Norton-Wright, has been adopted by RISC-V International as their reference formal model.
For the base Armv8-A architecture, we previously developed (with Alastair Reid, then at Arm) an automatic translation from their internal (mechanised but non-formal) ASL instruction definition language to Sail, and validated the result by testing the Sail-generated C emulator across the Arm Architecture Compliance Kit (ACK) test suite; see our POPL 2019 paper.
3 Model-based test generation
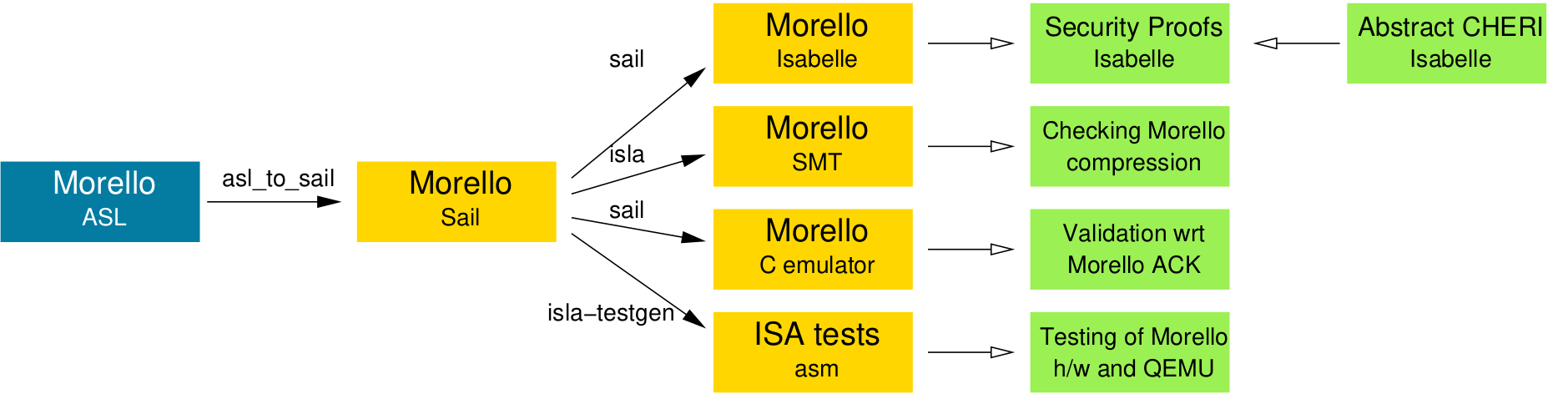
To provide confidence that the specifications and implementations match, and that the translations involved are correct, we used the Morello Sail specification to automatically generate a test suite with high specification coverage. This suite complements Arm’s ACK test suite for the Morello architecture, both in terms of coverage and our ability to share it. Indeed, we used it alone before access to the ACK was arranged.
As mentioned above, Sail provides tool support for test generation, as one of the use cases of rigorous architecture specifications: The test generation tool uses the generic Isla symbolic execution engine for Sail to explore the possible execution paths of instructions, in combination with the Z3 SMT solver to find concrete input and output values for constructing tests. With this automatically generated test suite, we found a number of bugs in the original ASL specification, different implementations, and our tooling. Remarkably, none of these bugs had any impact on the security properties provided by capabilities. We also used this test suite as the basis for test-driven development of QEMU support for Morello and continue to use it for regression testing.
4 Machine-checked mathematical proof of whole-ISA security properties
The next step is to prove that the CHERI architecture designs enforce the intended protections. We did this first for CHERI-MIPS, as reported in our Security and Privacy 2019 paper and Kyndylan Nienhuis’s PhD thesis, and more recently for Morello, as reported in our ESOP 2022 paper.
The fundamental intended security property of CHERI architectures is reachable capability monotonicity: the available capabilities cannot be increased (irrespective of what code is running) during normal execution, i.e., they are monotonically decreasing. This is a whole-system property about arbitrary machine execution, and conventional testing techniques cannot provide high assurance that an architecture satisfies it – testing can only check some execution paths of some test programs.
Instead, we develop machine-checked mathematical proof, which (unlike testing) can cover all possible cases of the execution of arbitrary code. We used the Isabelle/HOL proof assistant, which provides powerful tools for definitions and proofs in higher-order logic, following Milner’s LCF approach to ensure that its soundness relies only on that of a small proof kernel.
4.1 The specification
For CHERI-MIPS we used Isabelle definitions auto-generated from our L3 ISA definition, then for Morello we used Isabelle definitions auto-generated from a Sail version of the specification, itself translated from the Arm-internal ASL version.
The challenge here is the scale: CHERI-MIPS is around 7k lines of specification, while Morello is 62k lines of ASL, which translates to 210k lines of Isabelle. That Morello specification includes includes sequential semantics of the capability mechanisms and instructions, along with all of the Armv8-A AArch64 base architecture and its extensions supported by Morello, e.g. floating point and vector instructions, system registers, exceptions, user mode, system mode, hypervisor mode, some debugging features, and virtual-memory address translation. In a full architecture spec, even a single instruction is much more complex than one might imagine.
For example, below are parts of the semantics for the Morello LDR (literal) instruction for loading a capability from a program-counter-capability (PCC) relative address. Lines 1–6 are the relevant opcode pattern-match clause. That calls the decode function on Lines 8-13, which calls the execute function on Lines 15-24. That uses auxiliary function VACheckAddress (Lines 26–33) to check that the PCC capability (wrapped in a VirtualAddress structure) has the right bounds and permissions, raising an exception otherwise (Lines 51-55). MemC_read (Line 21) performs the load, and CapSquashPostLoadCap (Line 22) performs additional checks, in particular clearing the tag of the loaded capability if the authorising capability does not have capability load permission. C_set (Line 23) stores the result to the destination register.
1 function clause __DecodeA64 ((pc, ([bitone,bitzero,bitzero,bitzero,bitzero,bitzero,
2 bitone,bitzero,bitzero,bitzero,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_]
3 as __opcode)) if SEE < 99) = {
4 SEE = 99; let imm17 = Slice(__opcode, 5, 17); let Ct = Slice(__opcode, 0, 5);
5 decode_LDR_C_I_C(imm17, Ct)
6 }
7
8 val decode_LDR_C_I_C : (bits(17), bits(5)) -> unit
9 function decode_LDR_C_I_C (imm17, Ct) = {
10 let 't = UInt(Ct);
11 let offset : bits(64) = SignExtend(imm17 @ 0b0000, 64);
12 execute_LDR_C_I_C(offset, t)
13 }
14
15 val execute_LDR_C_I_C : forall ('t:Int),(0<='t & 't<=31). (bits(64),int('t)) -> unit
16 function execute_LDR_C_I_C (offset, t) = {
17 CheckCapabilitiesEnabled();
18 let base : VirtualAddress = VAFromCapability(PCC);
19 let address : bits(64) = Align(VAddress(base) + offset, CAPABILITY_DBYTES);
20 VACheckAddress(base, address, CAPABILITY_DBYTES, CAP_PERM_LOAD, AccType_NORMAL);
21 data : bits(129) = MemC_read(address, AccType_NORMAL);
22 let data : bits(129) = CapSquashPostLoadCap(data, base);
23 C_set(t) = data
24 }
25
26 val VACheckAddress : forall ('size : Int).
27 (VirtualAddress, bits(64), int('size), bits(64), AccType) -> unit
28 function VACheckAddress (base, addr64, size, requested_perms, acctype) = {
29 c : bits(129) = undefined;
30 if VAIsBits64(base) then { c = DDC_read() }
31 else { c = VAToCapability(base) };
32 __ignore = CheckCapability(c, addr64, size, requested_perms, acctype)
33 }
34
35 val CheckCapability : forall ('size : Int).
36 (bits(129), bits(64), int('size), bits(64), AccType) -> bits(64)
37 function CheckCapability (c, address, size, requested_perms, acctype) = {
38 let el : bits(2) = AArch64_AccessUsesEL(acctype);
39 let 'msbit = AddrTop(address, el);
40 let s1_enabled : bool = AArch64_IsStageOneEnabled(acctype);
41 addressforbounds : bits(64) = address; [...7 lines setting addressforbounds...]
42 fault_type : Fault = Fault_None;
43 if CapIsTagClear(c) then { fault_type = Fault_CapTag }
44 else if CapIsSealed(c) then { fault_type = Fault_CapSeal }
45 else if not_bool(CapCheckPermissions(c, requested_perms))
46 then { fault_type = Fault_CapPerm }
47 else if (requested_perms & CAP_PERM_EXECUTE) != CAP_PERM_NONE
48 & not_bool(CapIsExecutePermitted(c)) then { fault_type = Fault_CapPerm }
49 else if not_bool(CapIsRangeInBounds(c, addressforbounds, size[64 .. 0]))
50 then { fault_type = Fault_CapBounds };
51 if fault_type != Fault_None then {
52 let is_store : bool = CapPermsInclude(requested_perms, CAP_PERM_STORE);
53 let fault : FaultRecord = CapabilityFault(fault_type, acctype, is_store);
54 AArch64_Abort(address, fault)
55 };
56 return(address)
57 }4.2 The theorem
The Reachable Capability Monotonicity theorem we prove states (roughly) that software cannot escalate its privileges by forging capabilities that are not reachable from the starting state. Non-monotonic changes in the set of reachable capabilities are limited to the specific mechanisms defined for transferring control to another security domain, i.e. ISA exceptions or sealed capability invocations, and installing capabilities belonging to the new domain in the PCC (and possibly IDC) register. The monotonicity guarantee stops before such a domain transition happens.
4.3 The proof
The size of the Morello specification (210k lines of Isabelle definitions) pushes the limits of what interactive theorem provers like Isabelle can handle. In order to keep the machine-checked proof manageable, we factor it via a thin abstraction layer that breaks the overall monotonicity property down into local properties of each register and memory access that instructions perform. In particular, we prove that:
- Every capability written to a register is monotonically derivable via legal operations from the input capabilities of the instruction (with only the well-defined domain transition mechanisms allowed to perform specific non-monotonic capability writes).
- Every memory access is authorised by a capability with the right bounds and permissions.
With relatively simple proof infrastructure and automation, we can prove these properties for all instructions, and it is then straightforward to show that these instruction-local properties imply the whole-ISA monotonicity property.
The proof consists of around 37000 automatically generated lines, 8600 manually written lines, and 8900 lines for the abstract model, monotonicity proof, and proof tools. The proof executes in 7h20m CPU time on an i7-10510U CPU at 1.80GHz, but only half that real time thanks to parallel execution, with peak memory consumption of 18GB.
5 Design-time proof
Our Morello proof was developed in parallel with the detailed ISA design done by Arm. Our proof automation worked sufficiently well that we were able to keep up with weekly snapshots of the ASL specification while it was being developed, and feed back issues found to Arm. The main proof was completed before tape-out of the Morello silicon.
The main point of the proof was to provide high assurance that the Morello ISA design satisfies the intended property, not to find bugs, but in the process we did find three issues in the ASL specification that would have violated that property, along with other issues already known to Arm, and some functional bugs not directly affecting the security result. All were reported to Arm and fixed before tapeout.
6 Non-goals and limitations
For any formal statement about security, one always has to carefully understand exactly what it does and doesn’t say. We prove the specific result above, which substantially improves confidence in the design, but it is not a general (and nebulous!) statement that “Morello is secure”. In more detail:
- Our results establish confidence that the Morello instruction set architecture design satisfies its most fundamental intended security property. We do not address correctness of the Morello hardware implementation of that architecture, which would be an extremely challenging hardware verification task, beyond the current state of the art, and we do not cover system components that are not specified by the ISA itself, e.g. the Generic Interrupt Controller (GIC).
- The architecture, as usual, expresses only functional correctness properties, not timing or power properties, to allow hardware implementation freedom. Properties and proofs about the architecture therefore cannot address side channels (but see our discussion of side-channels and CHERI).
- We consider only the sequential architecture. Studying concurrency effects would require a more complex system model integrating the Morello sequential semantics with a whole-system concurrency memory model, which we leave to future work, but we expect the capability properties to be largely orthogonal to concurrency issues, as long as the write of a capability body and tag appear atomic.
- We assume an arbitrary but fixed translation mapping. CHERI capabilities are in terms of virtual addresses, so system software that manages translations has to be trusted or verified. We also assume that the privileged capability creation instructions are disabled and no external debugger is active, because these features can in general be used to circumvent the capability protections.
- Our capability monotonicity property is the most fundamental property one would expect to hold of a CHERI architecture, but it is by no means the only such property. However, stronger properties typically involve specific software idioms, e.g. calling conventions or exception handlers, and their proofs use techniques that have not yet been scaled up to full architectures.
- We prove monotonicity of the Morello specification formally in Isabelle, however, our proof depends on an SMT solver as an oracle for one lemma.
- Our conversion from ASL via Sail to Isabelle is not subject to verification, as neither ASL nor Sail have an independent formal semantics — their semantics is effectively defined by this translation. However, it is nontrivial, and there is the possibility of mismatches with the Sail-generated C emulator used for validation; we do not attempt to verify that correspondence.
- The ASL specification is subject to the limitations documented by Arm (Armv8-A F.c Appendix K14), e.g. with respect to implementation-defined behaviour.
7 Conclusion
The main Morello proof took only around 24 person-months, by two people, following around 23 person-months of preliminary work on model translation, Sail, and our CHERI abstraction. Test generation and ACK validation took an additional 17 person-months.
This work gives us machine-checked mathematical proofs of whole-ISA security properties of a full-scale industry architecture, at design time. To the best of our knowledge, this is the first demonstration that that is feasible. It significantly increases confidence in Morello, and, more generally, it demonstrates that rigorous engineering of key abstractions, at a production industry-architecture scale, is viable.
8 Acknowledgements
We thank all the members of the wider CHERI and Morello teams, for their work to make Morello a reality. This work was supported by the UK Industrial Strategy Challenge Fund (ISCF) under the Digital Security by Design (DSbD) Programme, to deliver a DSbDtech enabled digital platform (grant 105694), EPSRC programme grant EP/K008528/1 REMS, ERC Advanced Grant 789108 ELVER (Sewell), a Gates studentship (Nienhuis), Arm iCASE awards, EPSRC IAA KTF funds, the Isaac Newton Trust, the UK Higher Education Innovation Fund (HEIF), Thales E-Security, Microsoft Research Cambridge, Arm, Google, Google DeepMind, HP Enterprise, and the Gates Cambridge Trust. Approved for public release; distribution is unlimited. This work was supported by the Defense Advanced Research Projects Agency (DARPA) and the Air Force Research Laboratory (AFRL), under contracts FA8750-10-C-0237 (“CTSRD”), FA8750-11-C-0249 (“MRC2”), HR0011-18-C-0016 (“ECATS”), and FA8650-18-C-7809 (“CIFV”), as part of the DARPA CRASH, MRC, and SSITH research programs. The views, opinions, and/or findings contained in this report are those of the authors and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.