![[CHERI tablet photo]](https://www.lightbluetouchpaper.org/wp-content/uploads/2015/09/20140116-beripad-ctsrd-slides-thickness.jpg)
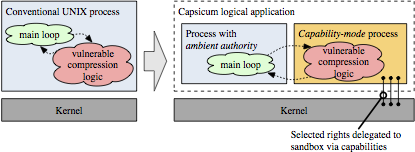
Compartmentalisation is an important form of vulnerability mitigation: it accepts that vulnerabilities are inevitably present in software, and that exploit mitigation techniques (such as stack canaries, ASLR) are limited in effectiveness given an attacker that learns and adapts to exploit-specific defenses. As deployed in applications such as the Chromium web browser, OpenSSH, and many Mac OS X/iOS components, compartmentalisation implements the principle of least privilege: isolated software components are granted only the rights they require to operate — when they are compromised, they yield only those limited rights to the attacker, and have fewer further attack surfaces available. Attackers must find and exploit more vulnerabilities to gain full rights to a system. However, deployment of compartmentalisation has been limited to only the most critical applications for both programmability and performance reasons, and often developers find ourselves place compartment boundaries at partition points in applications that are convenient for performance, rather than for security or software engineering. For example, in our earlier Capsicum OS-based compartmentalisation model, we ended up compartmentalising the gzip command, rather than the zlib library that we’d hoped to compartmentalise, because the library interface accepted memory buffers rather than file descriptors, whereas within the gzip code, there was a convenient boundary for file-descriptor delegation. These problems arise from the hardware structures we use to create isolation and implement sharing: virtual memory (VM) based on memory-management units (MMUs) and their translation-lookaside buffers (TLBs), which were designed to provide full virtualisation and strong isolation — rather than support tightly integrated software components with frequent interactions.
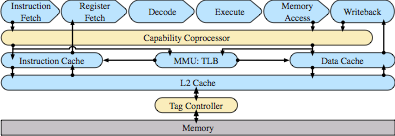
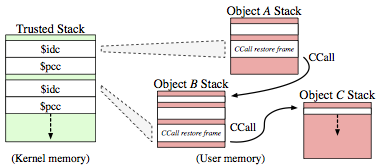
To address these concerns, we’ve proposed architectural extensions, known as Capability Hardware Enhanced RISC Instructions (CHERI), that augment conventional RISC ISAs to provide strong, fine-grained memory protection. Our prior papers have explored the architectural and micro-architectural foundations for an in-address-space capability system (ISCA 2014), as well as C-language semantics that must be supported to deploy CHERI within current, large-scale, C-language source-code bases (ASPLOS 2015). However, these were all steps on the path to a larger goal: using CHERI capabilities to construct isolated compartments within UNIX processes, and to allow sharing of data using capability (pointer) delegation between compartments, rather than requiring the use of awkward VM-based shared memory or UNIX IPC. In our new IEEE S&P paper, we describe how CHERI capabilities held by threads within a process can enumerate a set of object capabilities within a virtual address space — object instances consist of a class, encapsulated in an ELF binary, and per-instance data, a la object-oriented programming. Minor extensions to the CHERI ISA introduce support for sealed code and data capabilities, and a hardware-assisted call/return mechanism allows the OS to implement domain transition between potentially mutually distrusting objects. We use a synchronous model that aligns well with current C-language code structures, and introduce a trusted stack allowing reliable return — but others (e.g., asynchronous closures) would certainly be possible as well.
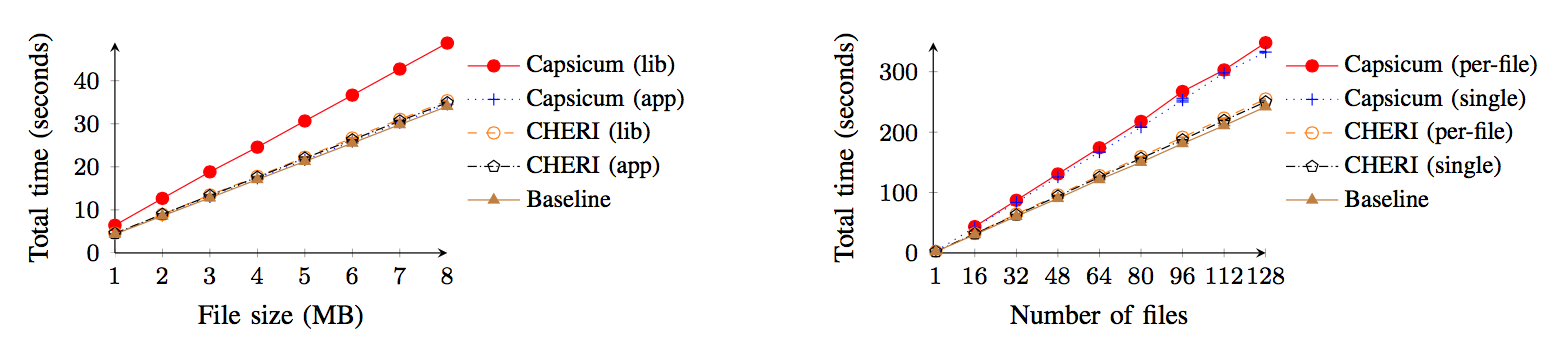
The results are convincing: our approach offers vastly improved performance (especially in terms of VM overhead) and programmability (programmers can now set up sharing using C pointers, data structures, and memory allocation). Using an FPGA-based hardware prototype, we booted the CheriBSD operating system, compiled with CHERI-enhanced Clang/LLVM, and demonstrated fine-grained sandboxing within applications such as tcpdump, where with negligible increased cost we can now sandbox the processing of individual packets retrieved from the network-interface card. With UNIX-based models, such as Capsicum, which uses only conventional hardware, multiple per-packet security-domain transitions would be infeasible while retaining a modicum of performance. We evaluate this work in terms of vulnerability mitigation: privileges gained, information leaked, etc, with respect to (many) past reported vulnerabilities. As well as having a very low domain-switch cost, using the same address space for domains means little increase in page-table size or TLB footprint, making sharing data extremely cheap compared to conventional virtual memory, which incurs greater cost as greater sharing takes place (whether via message passing or shared memory). Another key concept in CHERI is incremental deployability, where current software models (such as virtual memory, the C language) can have CHERI support ‘slid in’ for software we trust the least (e.g., video CODECs) or depend on the most (e.g., core system libraries) without perturbing the global software stack. We demonstrate this via a CHERI compartmentalized zlib: unmodified zlib consumers, such as gzip and PNG manipulation tools, experience not only minimal performance overhead, but also no change to zlib’s binary interfaces.
The slides from my talk are available on our project website; full details can be found in our paper. Technical reports, including our CHERI ISA specification (this paper corresponds to CHERI ISAv3), and our prior papers, can be found on the CTSRD project publications page. While implemented using a MIPS-based prototype on FPGA, our approach should be portable to other contemporary RISC ISAs such as ARMv8 or RISC-V with suitable but minor localisation. Our hardware and software designs are available as open source — and we continue to extend (and refine) our approach — with particular interest in reducing architectural and micro-architectural costs, software analysis and transformation for compartmentalisation, and formal verification. This work, performed at the University of Cambridge and SRI International, was joint with Jonathan Woodruff (Cambridge), Peter G. Neumann (SRI), Simon W. Moore (Cambridge), Jonathan Anderson (Memorial), David Chisnall (Cambridge), Nirav Dave (SRI), Brooks Davis (SRI), Khilan Gudka (Cambridge), Ben Laurie (Google), Steven Murdoch (UCL), Robert Norton (Cambridge), Michael Roe (Cambridge), Stacey Son (Dev Random), and Munraj Vadera (Cambridge). CHERI has been supported by our joint DARPA CTSRD and DARPA MRC2 projects, the EPSRC REMS Programme Grant [EP/K008528/1], the Isaac Newton Trust, the UK Higher Education Innovation Fund (HEIF), Thales E-Security, and a Focused Research Award from Google.
Thank you kind people. I so much wanted a scalable MAC for hard-but-straightforward tasks like running an isolated banking app as a compartment. Touched on at http://gtalug.org/meeting/2014-01/