Petr Svenda et al from Masaryk University in Brno won the Best Paper Award at this year’s USENIX Security Symposium with their paper classifying public RSA keys according to their source.
I really like the simplicity of the original assumption. The starting point of the research was that different crypto/RSA libraries use slightly different elimination methods and “cut-off” thresholds to find suitable prime numbers. They thought these differences should be sufficient to detect a particular cryptographic implementation and all that was needed were public keys. Petr et al confirmed this assumption. The best paper award is a well-deserved recognition as I’ve worked with and followed Petr’s activities closely.
The authors created a method for efficient identification of the source (software library or hardware device) of RSA public keys. It resulted in a classification of keys into more than dozen categories. This classification can be used as a fingerprint that decreases the anonymity of users of Tor and other privacy enhancing mailers or operators.
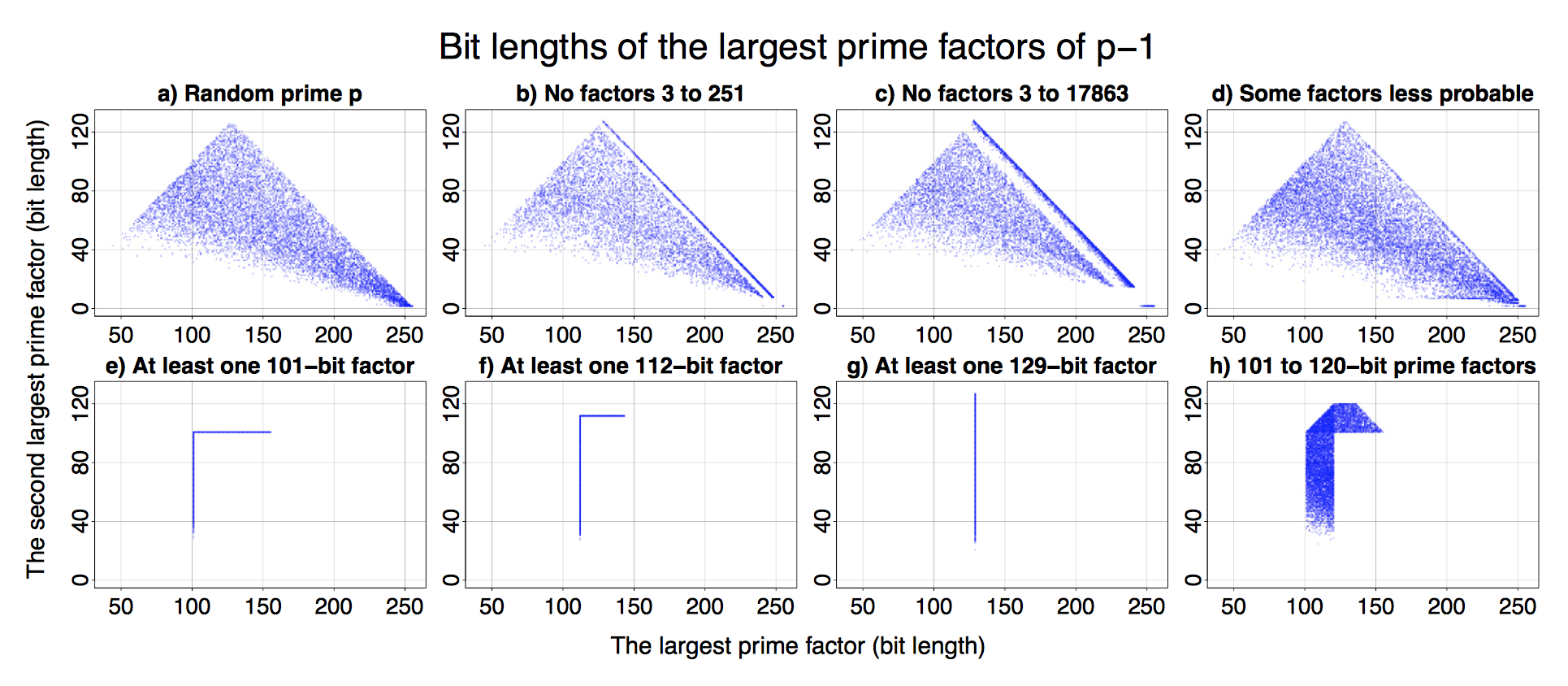
The graphs extracted from: The Million Key Question – Investigating The Origins of RSA Public Keys (follow the link for more).
All that is a result of an analysis of over 60 million freshly generated keys from 22 open- and closed-source libraries and from 16 different smart-cards. While the findings are fairly theoretical, they are demonstrated with a series of easy to understand graphs (see above).
I can’t see an easy way to exploit the results for immediate cyber attacks. However, we started looking into practical applications. There are interesting opportunities for enterprise compliance audits, as the classification only requires access to datasets of public keys – often created as a by-product of internal network vulnerability scanning.
An extended version of the paper is available from http://crcs.cz/rsa.