There are many different ways to represent the same text in Unicode. We’ve previously exploited this encoding-visualization gap to craft imperceptible adversarial examples against text-based machine learning systems and invisible vulnerabilities in source code.
In our latest paper, we demonstrate another attack that exploits the same technique to target Google Search, Bing’s GPT-4-powered chatbot, and other text-based information retrieval systems.
Consider a snake-oil salesman trying to promote a bogus drug on social media. Sensible users would do a search on the alleged remedy before ordering it, and sites containing false information would normally be drowned out by genuine medical sources in modern search engine rankings.
But what if our huckster uses a rare Unicode encoding to replace one character in the drug’s name on social media? If a user pastes this string into a search engine, it will throw up web pages with the same encoding. What’s more, these pages are very unlikely to appear in innocent queries.
The upshot is that an adversary who can manipulate a user into copying and pasting a string into a search engine can control the results seen by that user. They can hide such poisoned pages from regulators and others who are unaware of the magic encoding. These techniques can empower propagandists to convince victims that search engines validate their disinformation.
This week’s COVID briefing paper (COVIDbriefing-22.pdf) resumes the Cybercrime Centre’s COVID briefing series, which began in July 2020 with the aim of sharing short on-going updates on the impacts of the pandemic on cybercrime.
The reason for restarting this series is a recent personal experience while navigating through the government’s requirements on COVID-19 testing for international travel. I observed great variation in the quality of website design and cannot help but put on my academic hat to report on what I found.
The quality of some websites is so poor that it hard to distinguish them from fraudulent sites — that is they have many of the features and characteristics that consumers have been warned to pay attention to. Compounded with the requirement to provide personally identifiable information there is a risk that fraudulent sites will indeed spring up and it will be unsurprising if consumers are fooled.
The government needs to set out minimum standards for the websites of firms that they approve to provide COVID-19 testing — especially with the imminent growth in demand that will come as the UK’s travel rules are eased.
When you are a medical doctor, friends and family invariably ask you about their aches and pains. When you are a computer specialist, they ask you to fix their computer. About ten years ago, most of the questions I was getting from friends and family as a security techie had to do with frustration over passwords. I observed that what techies had done to the rest of humanity was not just wrong but fundamentally unethical: asking people to do something impossible and then, if they got hacked, blaming them for not doing it.
So in 2011, years before the Fido Alliance was formed (2013) and Apple announced its smartwatch (2014), I published my detailed design for a clean-slate password replacement I calledPico, an alternative system intended to be easier to use and more secure than passwords. The European Research Council was generous enough to fund my vision with a grant that allowed me to recruit and lead a team of brilliant researchers over a period of five years. We built a number of prototypes, wrote a bunch of papers, offered projects to a number of students and even launched a start-up and thereby learnt a few first-hand lessons about business, venture capital, markets, sales and the difficult process of transitioning from academic research to a profitable commercial product. During all those years we changed our minds a few times about what ought to be done and we came to understand a lot better both the problem space and the mindset of the users.
When you visit a website, your web browser provides a range of information to the website, including the name and version of your browser, screen size, fonts installed, and so on. Website authors can use this information to provide an improved user experience. Unfortunately this same information can also be used to track you. In particular, this information can be used to generate a distinctive signature, or device fingerprint, to identify you.
A device fingerprint allows websites to detect your return visits or track you as you browse from one website to the next across the Internet. Such techniques can be used to protect against identity theft or credit card fraud, but also allow advertisers to monitor your activities and build a user profile of the websites you visit (and therefore a view into your personal interests). Browser vendors have long worried about the potential privacy invasion from device fingerprinting and have included measures to prevent such tracking. For example, on iOS, the Mobile Safari browser uses Intelligent Tracking Prevention to restrict the use of cookies, prevent access to unique device settings, and eliminate cross-domain tracking.
We have developed a new type of fingerprinting attack, the calibration fingerprinting attack. Our attack uses data gathered from the accelerometer, gyroscope and magnetometer sensors found in smartphones to construct a globally unique fingerprint. Our attack can be launched by any website you visit or any app you use on a vulnerable device without requiring any explicit confirmation or consent from you. The attack takes less than one second to generate a fingerprint which never changes, even after a factory reset. This attack therefore provides an effective means to track you as you browse across the web and move between apps on your phone.
One-minute video providing a demo and describing how the attack works
Our approach works by carefully analysing the data from sensors which are accessible without any special permissions on both websites and apps. Our analysis infers the per-device factory calibration data which manufacturers embed into the firmware of the smartphone to compensate for systematic manufacturing errors. This calibration data can then be used as the fingerprint.
In general, it is difficult to create a unique fingerprint on iOS devices due to strict sandboxing and device homogeneity. However, we demonstrated that our approach can produce globally unique fingerprints for iOS devices from an installed app: around 67 bits of entropy for the iPhone 6S. Calibration fingerprints generated by a website are less unique (around 42 bits of entropy for the iPhone 6S), but they are orthogonal to existing fingerprinting techniques and together they are likely to form a globally unique fingerprint for iOS devices. Apple adopted our proposed mitigations in iOS 12.2 for apps (CVE-2019-8541). Apple recently removed all access to motion sensors from Mobile Safari by default.
We presented this work on 21st May at IEEE Symposium on Security and Privacy 2019. For more details, please visit the SensorID website and read our paper:
I’m at IMC 2017 at Queen Mary University of London, and will try to liveblog a number of the sessions that are relevant to security in followups to this post.
We’re looking for a Chief Information Security Officer. This isn’t a research post here at the lab, but across the yard in University Information Services, where they manage our networks and our administrative systems. There will be opportunities to work with security researchers like us, but the main task is protecting Cambridge from all sorts of online bad actors. If you would like to be in the thick of it, and you know what you’re doing, here’s how you can apply.
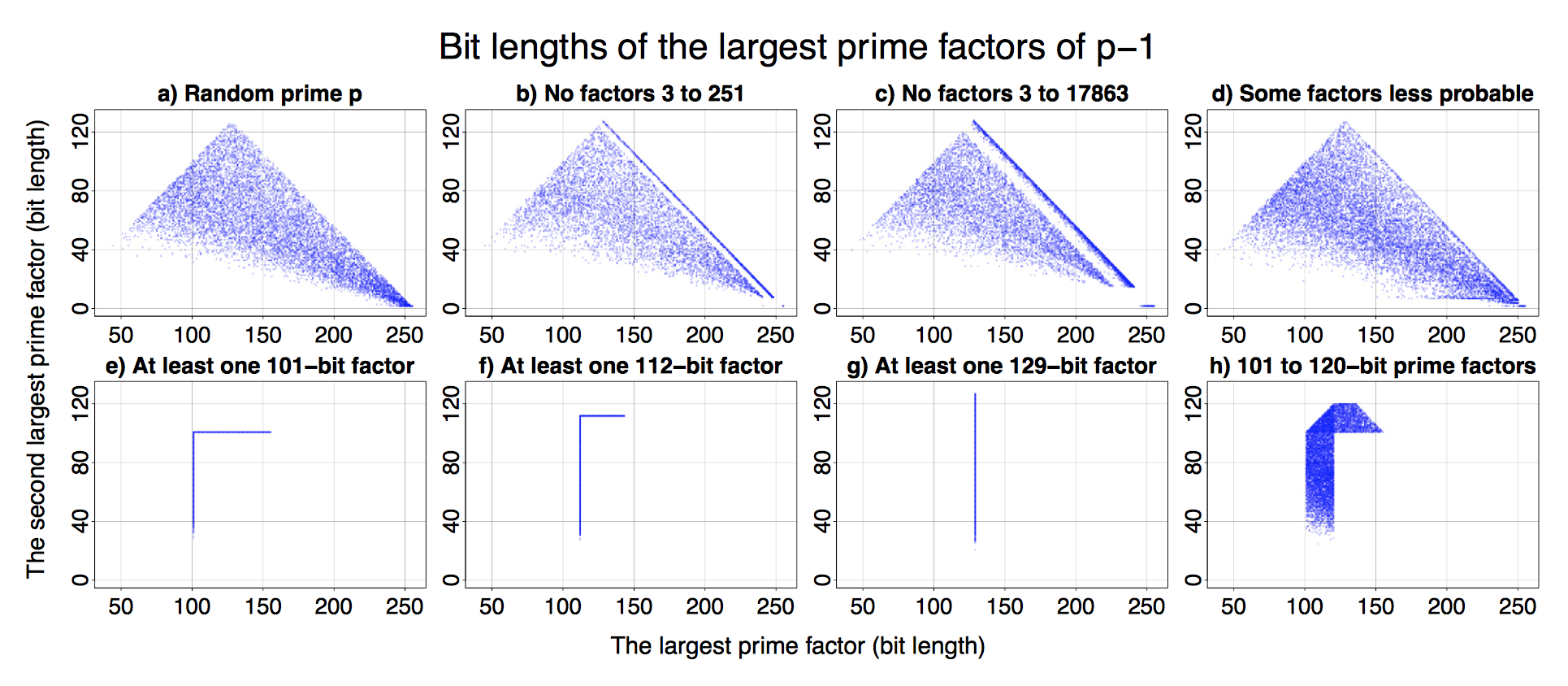
I really like the simplicity of the original assumption. The starting point of the research was that different crypto/RSA libraries use slightly different elimination methods and “cut-off” thresholds to find suitable prime numbers. They thought these differences should be sufficient to detect a particular cryptographic implementation and all that was needed were public keys. Petr et al confirmed this assumption. The best paper award is a well-deserved recognition as I’ve worked with and followed Petr’s activities closely.
The authors created a method for efficient identification of the source (software library or hardware device) of RSA public keys. It resulted in a classification of keys into more than dozen categories. This classification can be used as a fingerprint that decreases the anonymity of users of Tor and other privacy enhancing mailers or operators.
All that is a result of an analysis of over 60 million freshly generated keys from 22 open- and closed-source libraries and from 16 different smart-cards. While the findings are fairly theoretical, they are demonstrated with a series of easy to understand graphs (see above).
I can’t see an easy way to exploit the results for immediate cyber attacks. However, we started looking into practical applications. There are interesting opportunities for enterprise compliance audits, as the classification only requires access to datasets of public keys – often created as a by-product of internal network vulnerability scanning.
I am at the Privacy Enhancing Technologies Symposium (PETS 2016) in Darmstadt until Friday, and will try to liveblog some of the sessions in followups to this post. (I can’t do them all as there are some parallel sessions.)
A lot of people are starting to ask about the security and privacy implications of the “Internet of Things”. Once there’s software in everything, what will go wrong? We’ve seen a botnet recruiting CCTV cameras, and a former Director of GCHQ recently told a parliamentary committee that it might be convenient if a suspect’s car could be infected with malware that would cause it to continually report its GPS position. (The new InvestigatoryPowersBill will give the police and the spooks the power to hack any device they want.)
So here is the video of a talk I gave on The Internet of Bad Things to the Virus Bulletin conference. As the devices around us become smarter they will become less loyal, and it’s not just about malware (whether written by cops or by crooks). We can expect all sorts of novel business models, many of them exploitative, as well as some downright dishonesty: the recent Volkswagen scandal won’t be the last.
But dealing with pervasive malware in everything will demand new approaches. Our approach to the Internet of Bad Things includes our new Cambridge Cybercrime Centre, which will let us monitor bad things online at the kind of scale that will be required.